
深入理解AI基础模型:迁移学习与微调
在人工智能的世界中,迁移学习是一种强大的方法。它利用已有模型的知识来适应新的任务,类似于一个学生用他已有的知识去理解新的科目。这种方法的优势在于可以减少训练数据的需求,降低计算资源的消耗,并加快模型收敛的速度。
微调是迁移学习的进一步应用,专注于对模型进行特定任务的调整。就像为学生提供专门的辅导,帮助他在某个领域中更加出色。微调使模型在特定任务中表现得更精准。
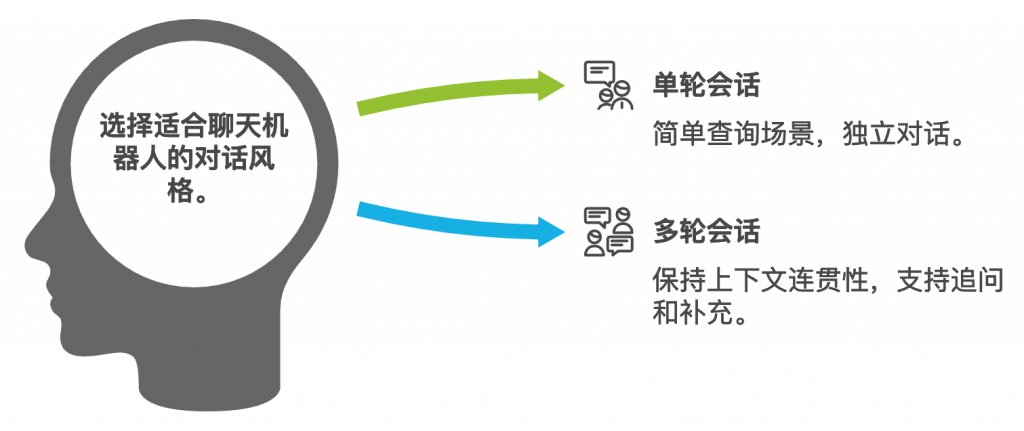
在指令式微调中,我们有两种会话方式:单轮会话和多轮会话。单轮会话是一种一问一答的形式,每次对话相互独立,适合简单的查询场景。而多轮会话则保持上下文的连贯性,支持追问和补充,适合更复杂的交互场景。
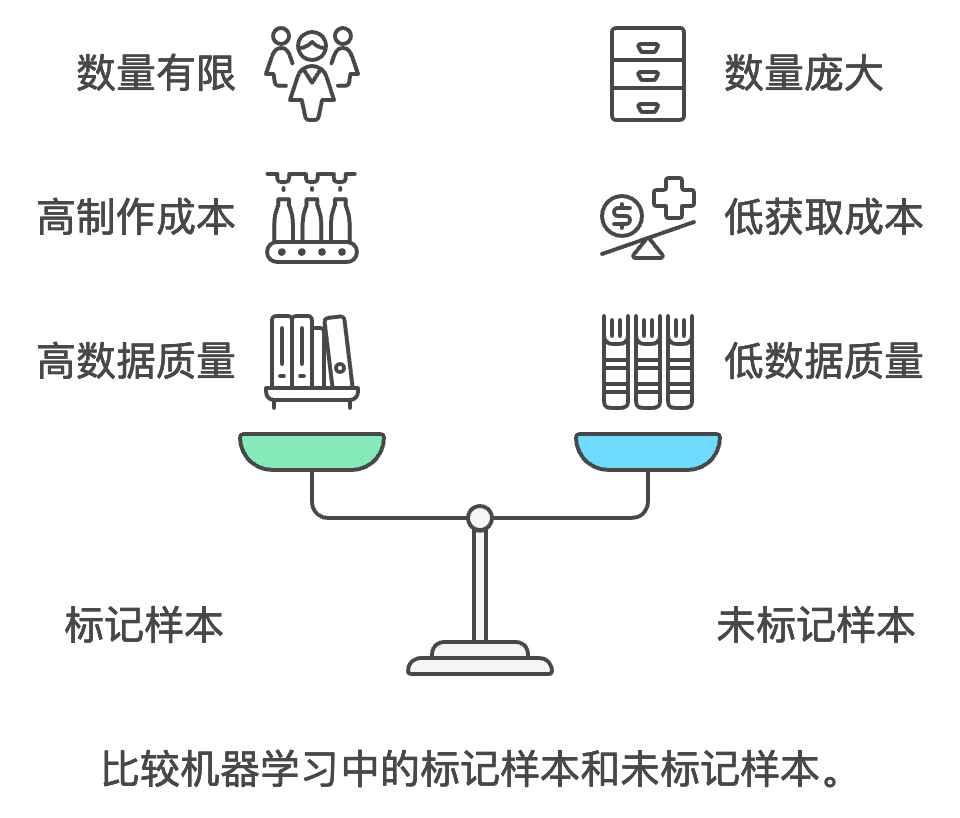
数据在AI训练中扮演着重要角色。标记样本是指带有正确答案的数据,用于微调模型。比如,输入”患者出现发热、咳嗽症状”时,标记的输出可能是”建议进行发烧检测,并及时就医”。这些数据质量高,但制作成本也高,适用于有监督学习。
相对而言,未标记样本是没有标注答案的原始数据,如大量文本文档、网页内容和对话记录。这些数据获取成本低、数量庞大,适用于无监督学习,通过这些数据,预训练模型可以提升其基础能力。
结合这些概念,AI模型能够通过不同的训练和调整方式,更好地理解和处理各种任务和对话。在现代AI应用中,了解并善用这些技术,将大大提高模型的效率和效果。
迁移学习(Transfer Learning)
- 定义:将一个领域学到的知识迁移到另一个相关领域
- 优势:
- 减少训练数据需求
- 降低计算资源消耗
- 加快模型收敛速度
单轮和多轮会话
- 单轮会话:
- 一问一答的形式
- 每次对话相互独立
- 适合简单查询场景
- 多轮会话:
- 保持上下文连贯性
- 支持追问和补充
- 适合复杂交互场景
标记样本和未标记样本
标记样本(Labeled Samples)
- 定义:已经人工标注了正确答案或期望输出的训练数据
- 示例:
- 输入:”患者出现发热、咳嗽症状”
- 标记:”建议进行发烧检测,并及时就医”
- 特点:
- 数据质量高
- 制作成本高
- 适用于有监督学习
未标记样本(Unlabeled Samples)
- 定义:没有人工标注答案的原始数据
- 示例:
- 大量的文本文档
- 网页内容
- 对话记录
- 特点:
- 获取成本低
- 数量庞大
- 适用于无监督学习
课程





轻松入门AWS云计算2025
私人 815- 模型微调和持续预训练的区别AWS知识点
- 亚马逊API网关03-计算与负载均衡 通过AWS SAP认证
- 亚马逊EKS03-计算与负载均衡 通过AWS SAP认证
- S3加密04-存储 通过AWS SAP认证
- S3版本控制,复制和生命周期配置04-存储
- AWS Lambda – 函数版本,别名,API网关,CodeDeploy协同03-计算与负载均衡 通过AWS SAP认证
- AWS Lambda – 同步/异步调用,事件源,目标03-计算与负载均衡 通过AWS SAP认证
- AWS Lambda – 第二部分03-计算与负载均衡 通过AWS SAP认证
- AWS Lambda – 第一部分03-计算与负载均衡 通过AWS SAP认证
- 会话状态和粘性会话03-计算与负载均衡 通过AWS SAP认证
- 弹性负载均衡器类型03-计算与负载均衡
- AWS Control Tower02-身份与联合身份验证 通过AWS SAP认证
- AWS Directory Service02-身份与联合身份验证 通过AWS SAP认证
- AWS SAP-C02 考试指南01-开始课程 通过AWS SAP认证
- RAG技术详解:一文看懂检索增强生成的工作原理未分类
- 深入理解AI基础模型:迁移学习与微调AWS知识点




0 responses on "深入理解AI基础模型:迁移学习与微调"